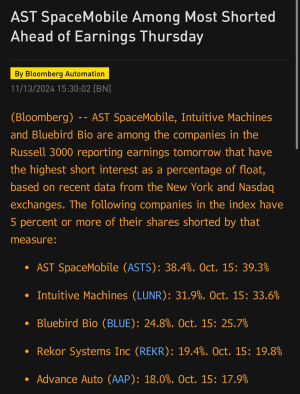
Paysafe, a leading specialized payments platform, today announced that its Skrill digital wallet has expanded its cryptocurrency offering to the U.S.
www.businesswire.com
Looked at their ratings and numbers, and since their price was so low I took the jump. If anyone else has any other insight on how they look please share.
Quick look at itled me to passing based off the numbers alone. Growth was too slow for a mature company. Maybe I need to look again.
congrats to all of you who had perspective and scaled into your best ideas during the correction. Still not out of the water, but things look good. Now make sure you keep perspective and don’t get fomo or do anything foolish. Know your timeframe and plan. I personally am doing nothing now. Just waiting for dca days to buy more JMIA, nvta, etc.
this is a great lesson on FSD with a deep learning company instead of mapping or lidar. Brilliant stuff.
Don’t hold a loser over owning a winner that you like better.
CURI has a good valuation and guidance, but if you don’t like it, or think you can make a better move elsewhere, nothing wrong with changing your mind.
Covid is going to increase adoption for digital wallets thanks to these vaccine passes and big events doing away with cash (Citi Field is cashless). Don’t miss this trend.
In our study published in Nature, we demonstrate how artificial intelligence research can drive and accelerate new scientific discoveries. We’ve built a dedicated, interdisciplinary team in hopes...
deepmind.com
Semiconductor Companies Leading the AI Revolution – Part I The Supply Chain, Leaders, and Startups
Hi Everyone,
This is the first premium subscriber-only article, so welcome! You can also access the article on my website. To save you all the pleasantries, I wanted to let you know the next premium article will be a company analysis.
Please make sure to share this newsletter, share this post, or subscribe (if you have not already) if you like the content! You can use the buttons here to do so: Share Seifel Capital Newsletter Share Subscribe now DISCLAIMER:
All investment strategies and investments involve the risk of loss. Nothing contained in this website should be construed as investment advice. Any reference to an investment's past or potential performance is not, and should not be construed as, a recommendation or as a guarantee of any specific outcome or profit.
AI Progress Depends on Semiconductors
My previous newsletter provided an overview of the AI microchip market. This article will attempt to identify which semiconductor companies will be the market leaders and what makes its technology so effective. This article will cover certain major players in relative depth, while covering other impactful companies in less detail. This is not by any means an all-encompassing list (that would be a very long read). This Part I will cover Design/IP companies, with other parts of the supply chain addressed in Part II. Unless otherwise stated, I procured this information from direct company sources (i.e. website, presentations, etc.) and refined this knowledge through discussions with one of the best semiconductor analysts I know. Introduction
This article will begin with a quick overview of the semiconductor supply chain (which I will elaborate on in a future article). This foundation will be helpful to fully understand the AI chip market players. I will mention the companies that will be discussed in this article within where it sits in the supply chain. My overarching view of AI and semiconductors is that AI progress depends on semiconductor technology advancements, and semiconductor industry growth hinges in large part on AI progress. Definitions Compiler: A computer program that translates (compiles) code written in one language (the source code) into another language (the target language). The target language ends up being the language, or instruction set, that can be understood and executed by the computer’s processors. Think of the compiler simply as a translator, from a more complex language used by humans/users to a more simple language that can be understood by computers. Run-Time: The amount of time it takes for a program to be executed, also known as the program lifecycle. Profiling: Software or program analysis, including “the space (memory) or time complexity of a program, the usage of particular instructions, or the frequency and duration of function calls.” Profiling tools are used to accomplish this analysis.
Semiconductor Supply Chain (Source: TSMC) Semiconductor Supply Chain I learned a lot about the global semiconductor supply chain from a report published by the Semiconductor Industry Association, which I will use to explain the supply chain here.
Research and Development (“R&D”): While the industry typically followed Moore’s Law for the majority of its existence, it has now moved into the “More than Moore” paradigm. R&D companies focused on enhancing processor speed and efficiency (lower power usage) at a lower cost to keep up with Moore’s Law. Simply, the focus was on increasing chip density – fitting more transistors on the same size chip. In More than Moore, companies are focusing on innovating in assembly and packaging to mitigate the physical limitations encountered by Moore’s Law.
Design: The output of R&D serves as an input for design companies. These design companies figure out how to leverage existing semiconductor technologies to meet customer demands and create further technological advancements. There are two sub-segments of Design:
Intellectual Property (“IP”) Companies: IP companies develop and license predesigned, modular circuits. These modular circuits are sold to other chip companies to be either integrated into their existing chip designs or added as a separate component to their chips.
Nvidia: Nvidia invented the graphics processing unit (“GPU”), which is at the core of computing for AI programs. Nvidia’s CUDA parallel computing platform is the platform of choice for software developers and engineers requiring general-purpose processing. CUDA serves as a major competitive advantage for Nvidia moving forward.
Hyperscalers: Google, Amazon, Microsoft, Apple, and the other hyperscalers are all investing significant resources in their own AI chips.
Arm Holdings: Arm is a leading IP company that utilizes Reduced Instruction Set Computing (“RISC“) design. RISC is a more simple, lower power-consumption, processing family compared to Intel’s x86. ARM is an acronym for Advanced RISC Machines.
Electronic Design Automation (“EDA”) Companies: These companies provide computer-aided design (“CAD”) and related services to the IP companies. This segment of the market has benefited from the hyperscalers and other new design companies entering the market. More importantly, EDAs will see increased utilization in the “More than Moore” paradigm as companies explore more efficient packaging technologies. The EDA market is a duopoly, comprised of Cadence Design Systems (“Cadence”) and Synopsys.
Manufacturing: These companies produce the designed chips, which requires significant engineering and technical expertise. The companies have can skillfully handle chemicals and materials utilized in the production process. These companies must achieve operating scale due to high fixed costs (barriers to entry along with the aforementioned expertise) and required recurring facility upgrades to keep up with advanced technologies.
Raw Material Suppliers: These companies provide the raw wafers and chemicals to manufacturing companies that are used to produce the chips.
Wafer Fab Equipment (“WFE”) Suppliers: Provides the specialized equipment and tools used in the production process.
Assembly, Testing, and Packaging: The companies performing these functions are known as outsourced assembly and test (“OSAT”). This vertical was historically labor-intensive, but the More than Moore paradigm is centered around developing advanced packaging innovations. I see this segment becoming more important and reliant on skilled labor and engineering capabilities.
Raw Material Suppliers: These companies provide the lead frames and packaging material to OSAT companies.
Equipment (“WFE”) Suppliers: Provides the specialized equipment and tools used in the assembly and packaging processes, as well as testing equipment.
The final takeaway, then, is that even as chip design is being affected by the new workloads of AI, the new process of chip design may have a measurable impact on the design of neural networks, and that dialectic may evolve in interesting ways in the years to come. Tiernan Ray
The Cloud TPU V3 can perform 420 teraFLOPS and contains 128GB of high-bandwidth memory (“HBM”). For clarity, this means the V3 can perform 420 TRILLION floating-point operations per second. That’s 420 x 1012 for those of you counting at home. The V3 represents a 133% increase in processing speed over the V2 TPU (180 teraFLOPS) and double the memory (64 GB of HBM). A pod of the V3 TPUs contains up to 2,048 TPU cores and 32 Tebibytes of total memory, resulting in over 100 petaFLOPs (over 100 QUADRILLION = 1015) of processing speed.
TPU v3 Pod with Better Performance DeepMind
Google’s subsidiary has been behind some of the most impressive achievements in AI. AlphaGo / AlphaGo Zero: The team at DeepMind developed a program that could beat a human at a board game. Ok, it’s a little more complicated and impressive than that. Go is an ancient Chinese game of strategic thinking. While the rules are simple, the game is extremely complex. There are 10170 possible board combinations, which is more than the number of atoms in the known universe! AlphaGo beat 18x Go world champion, Lee Sedol, 4 games to 1 in 2016. But that isn’t the most impressive feat of AlphaGo. The machine actually invented winning moves, proving that it was not just a probability-calculating program, but also had a creative element to it. The team went on to create AlphaGo Zero. While AlphaGo was trained by playing against other players, AlphaGo Zero was trained by playing against itself. From the blog:
AlphaGo Zero quickly surpassed the performance of all previous versions and also discovered new knowledge, developing unconventional strategies and creative new moves, including those which beat the World Go Champions Lee Sedol and Ke Jie. These creative moments give us confidence that AI can be used as a positive multiplier for human ingenuity. DeepMind Website
AlphaFold: DeepMind’s AlphaFold can be used to accurately predict 3D models of protein structures and has the potential to shorten research cycles across fields of biology. It was trained from 100,000 different known protein structures and sequences. It has developed to a point where it can now accurately predict a protein’s structure based on its amino acid sequence. Recently, AlphaFold was used to predict the protein structures of six of the 30 different protein structures comprising the SARS-CoV-2 virus. This helped scientists gain insight into 60% of the virus’ proteins that were poorly understood. This one practical use case is just an example of how AlphaFold is solving the protein folding problem. To summarize the scale of the problem:
But DNA only contains information about the sequence of amino acids – not how they fold into shape. The bigger the protein, the more difficult it is to model, because there are more interactions between amino acids to take into account. As demonstrated by Levinthal’s paradox, it would take longer than the age of the known universe to randomly enumerate all possible configurations of a typical protein before reaching the true 3D structure – yet proteins themselves fold spontaneously, within milliseconds. Predicting how these chains will fold into the intricate 3D structure of a protein is what’s known as the “protein folding problem” – a challenge that scientists have worked on for decades. AlphaFold Blog,AlphaFold: Using AI for Scientific Discovery
I currently am down to 18 stocks, but typically own 20-25. But I'm concentrated with 80% of my account being in my top 8-10 stocks. The rest being .5-3% positions that exist at low allocations as prove it plays that will either grow into a larger allocation through price appreciation or DCA'ing. As soon as my boats are filled in my next wave of DCA's (NVTA JMIA PD and potentially DIS NVDA), I'll start adding back some high risk small caps/SPACs at low allocations and get back to that 20-25 threshold. But I really don't see the point of being so spread out with 20 or 50 positions at 2% allocations each. You'll be very safe from a risk standpoint, but you'll be seeing killer % returns that aren't as killer as they should be $ wise. Size up your best ideas and have track it or prove it positions mixed in.
Short list for my high risk ideas that I would like to add back eventually:
CAPA CMIIU DMYI SRAC HOL REVHU ACUIF ASTS
But I don't need to own any of those because the reality is, they're 0 revs and high risk. Kind of **** you get after when you can't find good returns elsewhere.






 AI Progress Depends on Semiconductors
AI Progress Depends on Semiconductors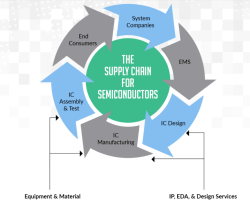 Semiconductor Supply Chain (Source: TSMC)
Semiconductor Supply Chain (Source: TSMC)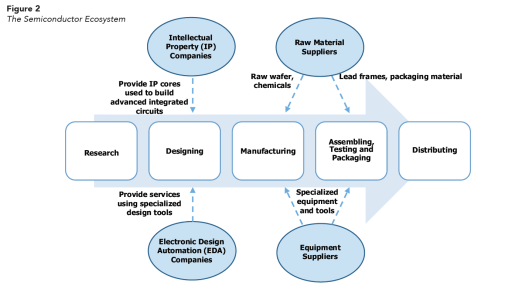 Supply Chain Overview – SIA
Supply Chain Overview – SIA
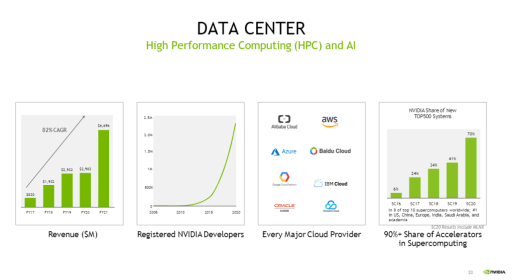 NVDA Data Center Business – Source: NVDA Investor Presentation
NVDA Data Center Business – Source: NVDA Investor Presentation AI TAM – Source: NVDA Investor Presentation
AI TAM – Source: NVDA Investor Presentation
 Widespread Usage of TensorFlow
Widespread Usage of TensorFlow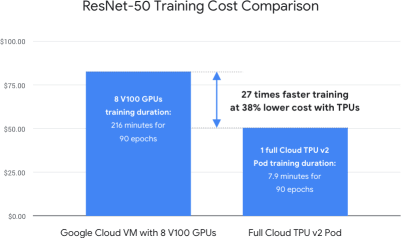 TPU v3 Pod with Better Performance
TPU v3 Pod with Better Performance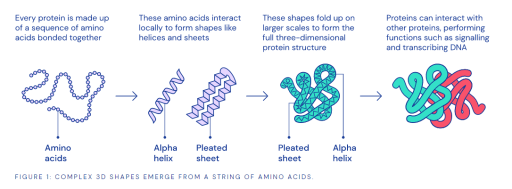 Why Protein Folding is So Complex
Why Protein Folding is So Complex



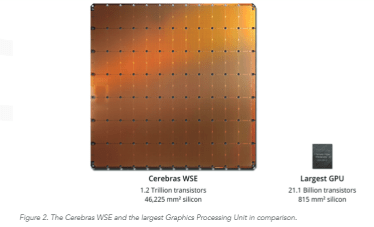 The Cerebras WSE is Massive
The Cerebras WSE is Massive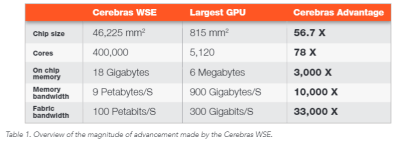 Cerebras WSE Comparison
Cerebras WSE Comparison